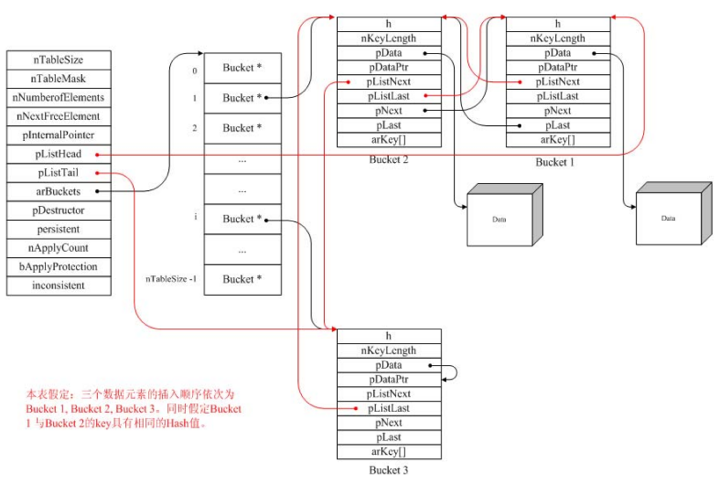
上图是PHP5 hashtable的实现
新的zval结构
struct _zval_struct {
zend_value value;
union {
struct {
ZEND_ENDIAN_LOHI_4(
zend_uchar type,
zend_uchar type_flags,
zend_uchar const_flags,
zend_uchar reserved
)
} v;
uint32_t type_info;
} u1;
union {
uint32_t var_flags;
uint32_t next; /* hash collision chain */
uint32_t cache_slot; /* literal cache slot */
uint32_t lineno; /* line number (for ast nodes) */
} u2;
};
按照posix标准,一般整形对应的*_t类型为: 1字节 uint8_t 2字节 uint16_t 4字节 uint32_t 8字节 uint64_t
PHP7中的zval结构包括三个部分。第一个是value。zend_value是一个联合体。保存任何类型的数据
第二部分是是四个字节的typeinfo.包含真正变量的类型。
第三部分是一个联合体。也是4个字节。辅助字段。
新的zval的实现不再使用引用计算。避免了两次计数/
新版HashTable的实现
# 老版本
typedef struct bucket {
ulong h; /* Used for numeric indexing */
uint nKeyLength;
void *pData;
void *pDataPtr;
struct bucket *pListNext; /* 指向哈希链表中下一个元素 */
struct bucket *pListLast; /* 指向哈希链表中的前一个元素 */
struct bucket *pNext; /* 相同哈希值的下一个元素(哈希冲突用) */
struct bucket *pLast; /* 相同哈希值的上一个元素(哈希冲突用) */
const char *arKey;
} Bucket;
# PHP7
typedef struct _Bucket {
zval val;
zend_ulong h; /* hash value (or numeric index) */
zend_string *key; /* string key or NULL for numerics */
} Bucket;
新的HashTable中,hash链表的构建工作由 HashTable->arHash 来承担,而解决hash冲突的链表则被放到了_zval_struct了
h 是hash的值。key 是字符串 val 是值。
比如arr["hello"] = "111"; hash(hello) = h hello =k
111 = val
typedef struct _HashTable {
union {
struct {
ZEND_ENDIAN_LOHI_3(
zend_uchar flags,
zend_uchar nApplyCount, /* 循环遍历保护 */
uint16_t reserve)
} v;
uint32_t flags;
} u;
uint32_t nTableSize; /* hash表的大小 */
uint32_t nTableMask; /* 掩码,用于根据hash值计算存储位置,永远等于nTableSize-1 */
uint32_t nNumUsed; /* arData数组已经使用的数量 */
uint32_t nNumOfElements; /* hash表中元素个数 */
uint32_t nInternalPointer; /* 用于HashTable遍历 */
zend_long nNextFreeElement; /* 下一个空闲可用位置的数字索引 */
Bucket *arData; /* 存放实际数据 */
uint32_t *arHash; /* Hash表 */
dtor_func_t pDestructor; /* 析构函数 */
} HashTable;
HashTable中另外一个非常重要的值arData,这个值指向存储元素数组的第一个Bucket
HashTable中有两个非常相近的值:nNumUsed、nNumOfElements,nNumOfElements表示哈希表已有元素数,那这个值不跟nNumUsed一样吗?为什么要定义两个呢?实际上它们有不同的含义,当将一个元素从哈希表删除时并不会将对应的Bucket移除,而是将Bucket存储的zval标示为IS_UNDEF,只有扩容时发现nNumOfElements与nNumUsed相差达到一定数量(这个数量是:ht->nNumUsed - ht->nNumOfElements > (ht->nNumOfElements >> 5))时才会将已删除的元素全部移除,重新构建哈希表。所以nNumUsed>=nNumOfElements。
arData数组保存了所有的buckets(也就是数组的元素),这个数组被分配的内存大小为2的幂次方,它被保存在nTableSize这个字段(最小值为8)。数组中实际保存的元素的个数被保存在nNumOfElements这个字段。注意这个数组直接包含Bucket结构。老的Hashtable的实现是使用一个指针数组来保存分开分配的buckets,这意味着需要更多的分配和释放操作(alloc/frees),需要为冗余信息及额外的指针分配内存。
hashtable 查找
arHash这个数组,这个数组由unit32_t类型的值组成。arHash数组跟arData的大小一样(都是nTableSize),并且都被分配了一段连续的内存区块。
hash函数(DJBX33A用于字符串的键,DJBX33A是PHP用到的一种hash算法)返回的hash值一般是32位或者64位的整型数,这个数有点大,不能直接作为hash数组的索引。首先通过求余操作将这个数调整到hashtable的大小的范围之内。 求余是通过计算hash & (ht->nTableSize - 1)
参考资料